

Very often customers initially build search for their website or application on top of Solr, but later run into challenges like elastic scaling and managing the Solr servers. This is a typical scenario we have observed in our years of search implementation experience. For such use cases, Amazon CloudSearch is a good choice. Amazon CloudSearch is a fully-managed service in the cloud that makes it easy to set up, manage, and scale a search solution for your website. To know more, please read the Amazon CloudSearch documentation.

We are seeing growing trend every year, organizations of various sizes are migrating their workloads to Amazon CloudSearch and leveraging the benefits of fully managed services. For example, Measured Search, an analytics and e-Commerce platform vendor, found it easier to migrate to Amazon CloudSearch rather than scale Solr themselves (see article for details).
Since Amazon CloudSearch is built on top of Solr, it exposes all the key features of Solr while providing the benefits of a fully managed service in the cloud such as auto-scaling, self-healing clusters, high availability, data durability, security and monitoring.
In this post, we provide step-by-step instructions on how to use the Apache Solr to Amazon CloudSearch Migration (S2C) tool to migrate from Apache Solr to Amazon CloudSearch. Before we get into detail, you can download the S2C tool in the below link.
Pre-Requisites
Before starting the migration, the following pre-requisites have to be met. The pre-requisites include installations and configuration on the migration server. The migration server could be the same Solr server or independent server that sits between your Solr server and Amazon CloudSearch instance.
Note:We recommend running the migration from the Solr server instead of independent server as it can save time and bandwidth. It is much better if the Solr server is hosted on EC2 as the latency between EC2 and CloudSearch is relatively less.
The following installations and configuration should be done on the migration server (i.e. your Solr server or any new independent server that connects between your Solr machine and Amazon CloudSearch).
- The application is developed using Java. Download and Install Java 8 .Validate the JDK path and ensure the environment variables like JAVA_HOME, classpath, path is set correctly.
- We assume you already have setup Amazon Web services IAM account. Please ensure the IAM user has right permissions to access AWS services like CloudSearch.
Note: If you do not have an AWS IAM account with above mentioned permissions, you cannot proceed further. - The IAM user should have AWS Access key and Secret key. In the application hosting server, set up the Amazon environment variables for access key and secret key. It is important that the application runs using the AWS environment variables.
To setup AWS environment variables, please read the below link. It is important that the tool is run using AWS environment variables.http://docs.aws.amazon.com/AWSSdkDocsJava/latest/DeveloperGuide/credentials.html
http://docs.aws.amazon.com/AWSSdkDocsJava/latest/DeveloperGuide/java-dg-roles.html
Alternatively, you can set the following AWS environment variables by running the commands below from Linux console.
export AWS_ACCESS_KEY=Access Key
export AWS_SECRET_KEY=Secret Key - Note: This step is applicable only if migration server is hosted on Amazon EC2.
If you do not have an AWS Access key and Secret key, you can opt for IAM role attached to an EC2 instance. A new IAM role can be created and attached to EC2 during the instance launch. The IAM role should have access to Amazon CloudSearch.
For more information, read the below link
http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/iam-roles-for-amazon-ec2.html - Download the migration utility ‘S2C’ (You would have completed this step earlier), unzip the tool and copy it in your working directory.Download Link: https://s3-us-west-2.amazonaws.com/s2c-tool/s2c-cli.zip
S2C Utility File
The downloaded ‘S2C’ migration utility should have the following sub directories and files.
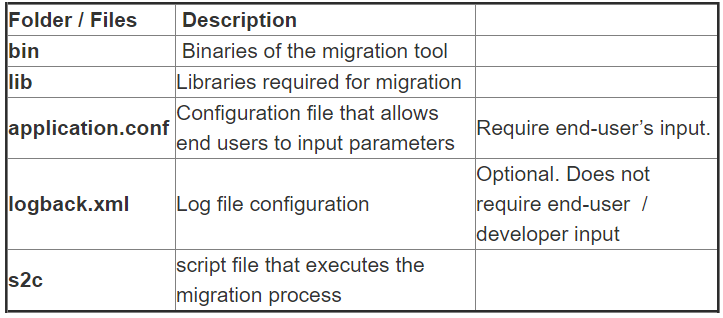
Configure only application.conf and logback.xml. Do not modify any other file.
Application.conf: The application.conf file has the configuration related to the new Amazon CloudSearch domain that will be created. The parameters configured in the application.conf file are explained in the table below.
Running the migration
Before launching the S2C migration tool, verify the following:
- Solr directory path – Make sure that the Solr directory path is valid and available. The tool cannot read the configuration if the path or directory is invalid.
- Solr configuration contents – Validate that the Solr configuration contents are correctly set inside the directory. Example: solrconfig.xml, schema.xml, stopwords.txt, etc.
- Make sure that the working directory is present in the file system and has write permissions for the current user. It can be an existing directory or a new directory. The working directory stores the fetched data from Solr and migration logs.
- Validate the disk size before starting the migration. If the available free disk space is lesser than the size of the Solr index, the fetch operations will fail.
For example, if the Solr index size is 7 GB, make sure that the disk has at least 10 GB to 20 GB of free space.
Note: The tool reads the data from Solr and stores in a temporary directory (Please see configuration wd = /tmp in the above table).
- Verify that the AWS environment variables are set correctly. The AWS environment variables are mentioned in the pre-requisites section above.
- Validate the firewall rules for IP address and ports if the migration tool is run from a different server or instance. Example: Solr default port 8983 should be opened to the EC2 instance executing this tool.
Run the following command from directory ‘{S2C filepath}’
Example: /build/install/s2c-cli/s2c or JVM_OPTS=”-Xms2048m -Xmx2048m” ./s2c (With heap size)
The above will invoke the shell ‘s2c’ script that starts the search migration process. The migration process is a series of steps that require user inputs as shown in the screen shots below.
Step 1: Parse the Solr schema The first step of migration prompts for a confirmation to parse the Solr schema and Solr configuration file. During this step, the application generates a ‘Run Id’ folder inside the working directory.
Example: /tmp/s2c/m1416220194655
The Run Id is a unique identifier for each migration. Note down the Run Id as you will need it to resume the migration in case of any failures.
Step 2: Schema conversion from Solr to CloudSearch.
The second step prompts confirmation to convert Solr schema to CloudSearch schema. Press any key to proceed further.
The second step will also list all the converted fields which are ready to be migrated from Solr to CloudSearch. If any fields are left out, this step will allow you to correct the original schema. User can abort the migration and identify the ignored fields, rectify the schema and re-run the migration again.The below screen shot shows the fields ready for CloudSearch migration.
Step 3: Data Fetch:
The third step prompts for confirmation to fetch the search index data from the Solr server. Press any key to proceed. This step will generate a temporary file which will be stored in the working directory. This temporary file will have all the fetched documents from the Solr index.
There is also option to skip the fetch process if all the Solr data is already stored in the temporary file. If this is the case, the prompt will look like the screenshot below.
Step 4: Data push to CloudSearch
The last and final step prompts for confirmation to push the search data from the temporary file store to Amazon CloudSearch. This step also creates the CloudSearch domain with the configuration specified in application.conf including desired instance type, replication count, and multi-AZ options.
If the domain is already created, the utility will prompt to use the existing domain. If you do not wish to use an existing domain, you can create a new CloudSearch domain using the same prompt.
Note:
The console does not prompt for any ‘CloudSearch domain name’ but instead it uses the domain name configured in the application.conf file.
Step 5: Resume (Optional)
During the migration steps, if there is any failure during the fetch operation, it can be resumed. This is illustrated in the screen shot below.
Step 6: Verification
Log into AWS CloudSearch management console to verify that the domain and index fields.
Features supported
- Support for other non-Linux environments is not available for now.
- Support for Solr Shards is not available for now. The Solr shard needs to be migrated separately.
- The install commands may vary for different Linux flavors. Example installing software, file editor command, permission set commands can be different for every Linux flavors. It is left to engineering team to choose the right commands during the installation and execution of this migration tool.
- Only fields configured as ‘stored’ in Solr schema.xml are supported. The non-stored fields are ignored during schema parsing.
- The document id (unique key) is required to have following attributes:
- Document ID should be 128 characters or less in size.
- Document ID can contain any letter, any number, and any of the following characters: _ – = # ; : / ? @ &
- The below link will help you to understand in data preparation before migrating to CloudSearch http://docs.aws.amazon.com/cloudsearch/latest/developerguide/preparing-data.html
- If the conditions are not met in a document, it will be skipped during migration. Skipped records are shown in the log file.
- If a field type (mapped to fields) is not stored, the stopwords mapped to that particular field type are ignored.
Example 1:
<field name=”description” type=”text_general” indexed=”true” stored=”true” />
Note: The above field ‘description’ will be considered for stopwords.Example
Example 2:
<field name=”fileName” type=”string” />
Note:
The above field ‘fileName’ will not be migrated and ignored in the stopwords.
Please do write your feedback and suggestions in the below comments section to improve this tool. The source code of the tool can be downloaded at https://github.com/8KMiles/s2c/. We have written a follow-up post in regard to that.
About the Authors
Dhamodharan P is a Senior Cloud Architect and at Principal Architect SecureKloud.



